

Author - Dheeraj Choudhary
I am an IT Professional with 11+ years of experience specializing in DevOps & Build and Release Engineering, Software configuration management in automating, build, deploy and release.
I blog about AWS and DevOps on my YouTube channel, which focuses on content such as, AWS, DevOps, open source, AI-ML and AWS community activities.

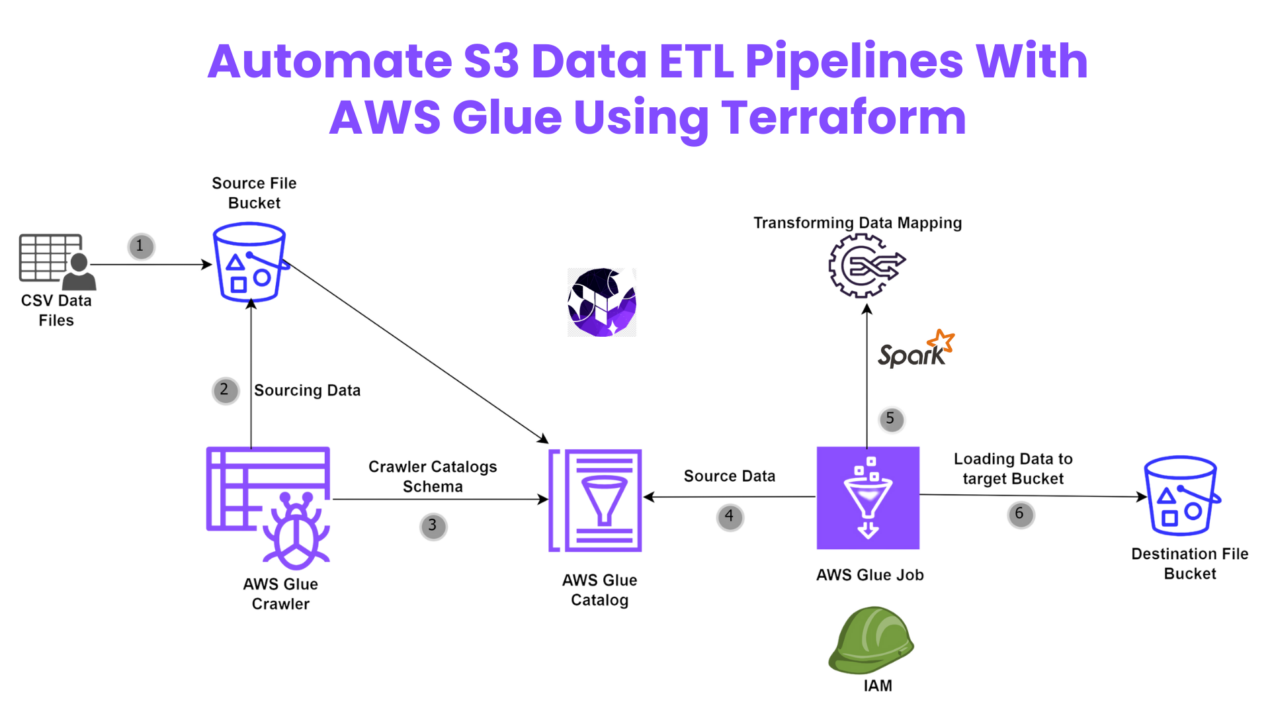
Automate S3 Data ETL Pipelines With AWS Glue Using Terraform
Discover how to automate your S3 data ETL pipelines using AWS Glue and Terraform in this step-by-step tutorial. Learn to efficiently manage and process your data, leveraging the power of AWS Glue for seamless data transformation. Follow along as we demonstrate how to set up Terraform scripts, configure AWS Glue, and automate data workflows.

Automating AWS Infrastructure with Terraform Functions
IntroductionManaging cloud infrastructure can be complex and time-consuming. Terraform, an open-source Infrastructure as Code (IaC) tool, si ...
You actually make it appear really easy together with your presentation but I
in finding this topic to be really something that I think I
would never understand. It sort of feels too complex and very huge for me.
I am looking forward in your subsequent submit, I will
try to get the hold of it! Najlepsze escape roomy
I was reading some of your content on this internet site and
I think this internet site is rattling instructive! Keep on posting.?
I like this site it’s a master piece! Glad I found this ohttps://69v.topn google.Raise your business
I used to be able to find good information from your articles.
Your style is unique in comparison to other folks I’ve read stuff from. Many thanks for posting when you have the opportunity, Guess I will just bookmark this site.
Hello there! I could have sworn I’ve been to your blog before but after looking at a few of the articles I realized it’s new to me. Anyways, I’m definitely delighted I came across it and I’ll be book-marking it and checking back often!
You have made some good points there. I checked on the net for more info about the issue and found most people will go along with your views on this web site.