
Diagrammatic Representation
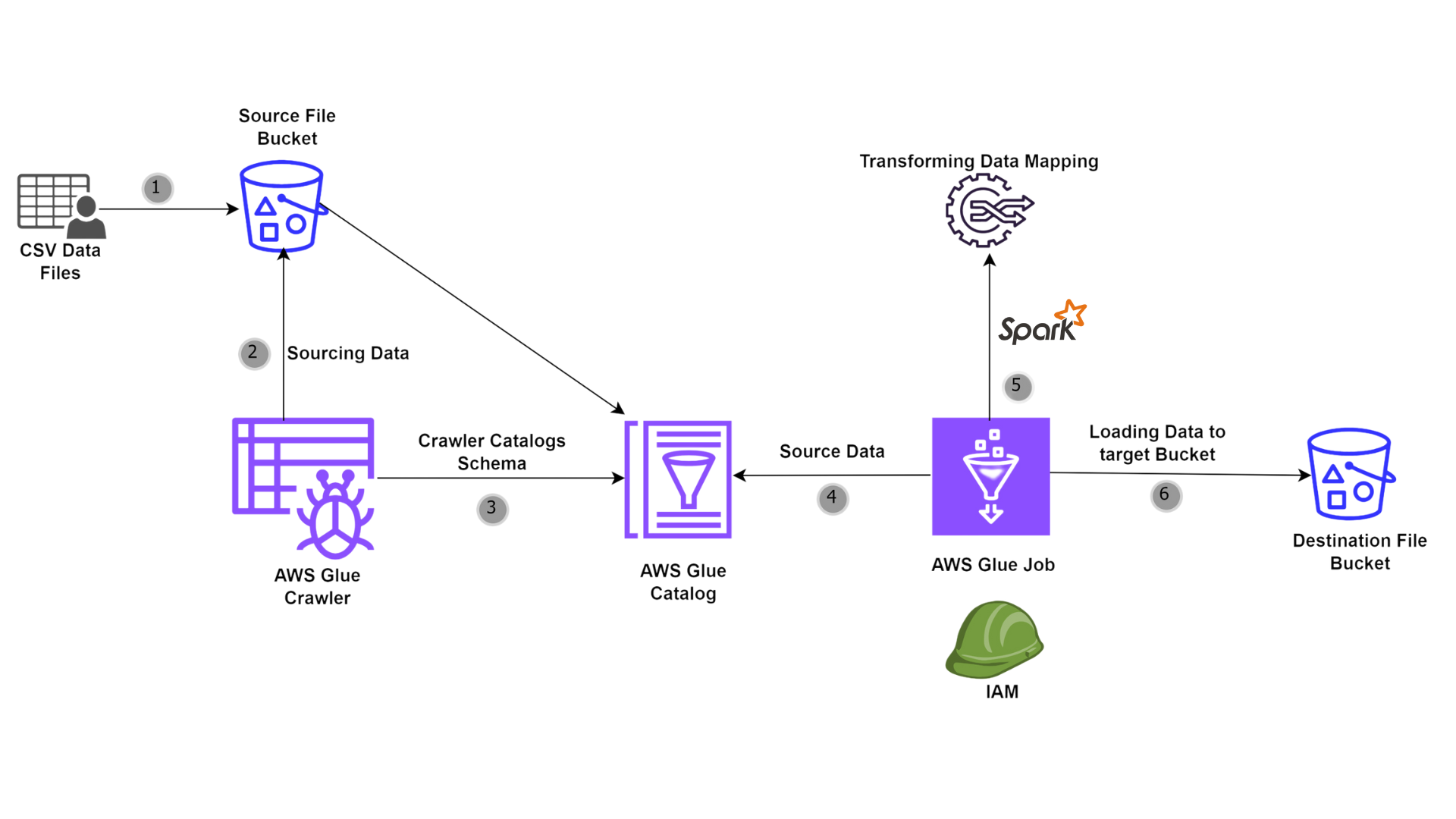 AWS Resource Overview
AWS Resource Overview
Amazon S3
Amazon S3 (Simple Storage Service) is an object storage service that provides scalability, data availability, security, and performance. S3 allows you to store and retrieve any amount of data from anywhere on the web. In this tutorial, S3 will be used for storing the raw data, the processed data, and the scripts required for AWS Glue jobs.
AWS Glue
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development. It includes several components that work together to handle ETL processes efficiently.
AWS Glue Data Catalog
The Glue Data Catalog is a central metadata repository that stores table definitions, job definitions, and other control information to help manage the ETL process. It organizes metadata into databases and tables, making it easier for Glue jobs to discover and access data.
AWS Glue Crawler
A Glue Crawler is a service that scans data in your specified data stores (such as S3), determines the schema of the data, and populates the Glue Data Catalog with metadata. This automated process simplifies managing and updating schemas, ensuring that your ETL jobs have the most current information about the data structure.
AWS Glue Job
A Glue Job is a business logic container for the ETL process. It can be written in Python or Scala and leverages Apache Spark for distributed processing. The job reads data from the Glue Data Catalog, applies transformations, and writes the output to the specified destination.
AWS Glue PySpark Scripting
PySpark is the Python API for Apache Spark. AWS Glue leverages PySpark scripts to define the ETL process. These scripts handle data extraction, transformation, and loading operations using Spark’s powerful distributed data processing capabilities.
AWS IAM
AWS Identity and Access Management (IAM) allows you to manage access to AWS services and resources securely. We’ll create an IAM role that AWS Glue will assume to interact with other AWS services like S3. This role ensures that Glue has the necessary permissions to read from the source bucket, write to the destination bucket, and log activities.
Why This Glue Pipeline is Required
Building a data pipeline using AWS Glue and Terraform automates the ETL process, making data processing more efficient and reliable. This setup is essential for several reasons:
Scalability: AWS Glue handles large datasets and scales automatically, ensuring that your ETL processes can handle growing data volumes.
Automation: Terraform automates the creation and management of AWS resources, reducing the risk of manual errors and increasing deployment consistency.
Cost-Effectiveness: AWS Glue is serverless, meaning you only pay for the resources you use. It eliminates the need to manage infrastructure, saving time and reducing operational costs.
Flexibility: The pipeline can be easily extended or modified to accommodate new data sources, transformation logic, and output destinations.
Industry-Level Use Cases
Data Warehousing: Organizations can use AWS Glue to extract data from various sources, transform it, and load it into data warehouses like Amazon Redshift for reporting and analysis.
Data Lakes: AWS Glue helps in building and managing data lakes by cataloging and transforming data stored in S3, making it readily available for analytics and machine learning.
ETL for Business Intelligence: Businesses can automate their ETL processes to ensure that data is consistently processed and made available for BI tools like Amazon QuickSight, ensuring timely and accurate insights.
Log Processing: AWS Glue can process large volumes of log data, transforming and enriching it before storing it in S3 or Elasticsearch for monitoring and analysis.


Author - Dheeraj Choudhary
Automate S3 Data ETL Pipelines With AWS Glue Using Terraform
Discover how to automate your S3 data ETL pipelines using AWS Glue and Terraform in this step-by-step tutorial. Learn to efficiently manage and process your data, leveraging the power of AWS Glue for seamless data transformation. Follow along as we demonstrate how to set up Terraform scripts, configure AWS Glue, and automate data workflows.

Automating AWS Infrastructure with Terraform Functions
IntroductionManaging cloud infrastructure can be complex and time-consuming. Terraform, an open-source Infrastructure as Code (IaC) tool, si ...

Deploying a Serverless Python Flask App on AWS ECS Fargate Using Terraform
Learn how to deploy a serverless Python Flask app on AWS ECS Fargate using Terraform. This step-by-step guide covers everything from setting up your AWS environment to writing Terraform scripts and managing your Flask application.

Build AWS Webteir With Terraform | DevOps Project
Learn how to deploy and manage your AWS Webteir infrastructure efficiently using Terraform. This comprehensive guide covers everything you need to know, from setting up your AWS environment to deploying applications and optimizing performance. Get expert tips, best practices, and troubleshooting advice to streamline your AWS Webteir deployment process and unlock the full potential of cloud computing for your business.